如何使用正则表达式从html字符串获取图像url
昂蒂哈(Thiha Aung)
我正在尝试使用正则表达式从html字符串中获取文本,这是我目前正在处理的:
extension String {
func regex (pattern: String) -> [String] {
do {
let regex = try NSRegularExpression(pattern: pattern, options: NSRegularExpressionOptions(rawValue: 0))
let nsstr = self as NSString
let all = NSRange(location: 0, length: nsstr.length)
var matches : [String] = [String]()
regex.enumerateMatchesInString(self, options: NSMatchingOptions(rawValue: 0), range: all) {
(result : NSTextCheckingResult?, _, _) in
if let r = result {
let result = nsstr.substringWithRange(r.range) as String
matches.append(result)
}
}
return matches
} catch {
return [String]()
}
}
模式是: <img[^>]+src\\s*=\\s*['\']([^'\"]+)['\"][^>]*>
我仍然无法从中获取图片网址,这意味着它返回了一个空数组。实际上我的html字符串中包含一张图片。UIWebView由于UITableView尺寸调整问题,我不想使用它。因此,我需要从中获取图片网址html并使用AlamofireImage在UIImageView中显示它。
任何帮助吗?这只是我需要获取的一个网址。
这是我的标签:
<img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
到 :
https://en.wikipedia.org/wiki/File:BH_LMC.png
Ro Me My
描述
<img\b(?=\s)(?=(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*?\ssrc=['"]([^"]*)['"]?)(?:[^>=]|='[^']*'|="[^"]*"|=[^'"\s]*)*"\s?\/?>
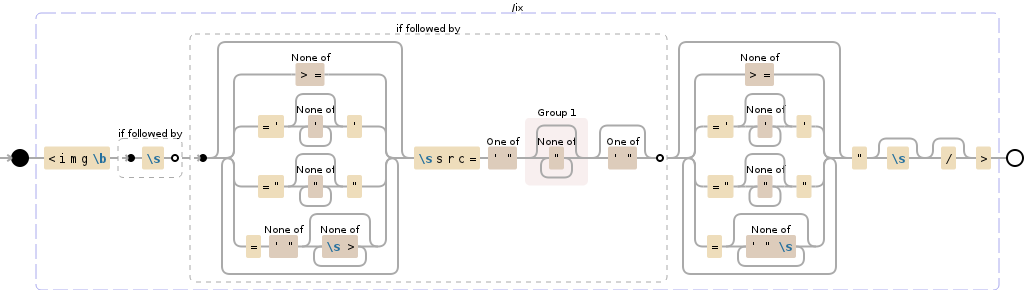
此正则表达式将执行以下操作:
- 此正则表达式捕获整个IMG标签
- 将源属性值放入捕获组1,如果引号不存在,则不加引号。
- 允许属性使用单引号,双引号或不带引号
- 可以修改以验证任意数量的其他属性
- 避免可能导致难以解析HTML的困难情况
例子
现场演示
https://regex101.com/r/qW9nG8/1
示范文本
请注意第一行中我们要查找特定机器人的困难边缘情况。
<img onmouseover=' if ( 6 > 3 { funSwap(" src="NotTheDroidYourLookingFor.jpg", 6 > 3 ) } ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
some text
<img src="http://website/someurl.jpeg" onload="img_onload(this);" />
more text
<img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
比赛样本
- 捕获组0获取整个IMG标签
- 捕获组1仅获取src属性值
[0][0] = <img onmouseover=' funSwap(" src='NotTheDroidYourLookingFor.jpg", data-pid) ; ' src="http://website/ThisIsTheDroidYourLookingFor.jpeg" onload="img_onload(this);" onerror="img_onerror(this);" data-pid="jihgfedcba" data-imagesize="ppew" />
[0][1] = http://website/ThisIsTheDroidYourLookingFor.jpeg
[1][0] = <img src="http://website/someurl.jpeg" onload="img_onload(this);" />
[1][1] = http://website/someurl.jpeg
[2][0] = <img src="https://en.wikipedia.org/wiki/File:BH_LMC.png"/>
[2][1] = https://en.wikipedia.org/wiki/File:BH_LMC.png
解释
NODE EXPLANATION
----------------------------------------------------------------------
<img '<img'
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the least amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)*? end of grouping
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
src= 'src='
----------------------------------------------------------------------
['"] any character of: ''', '"'
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
['"]? any character of: ''', '"' (optional
(matching the most amount possible))
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"\s]* any character except: ''', '"',
whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\/? '/' (optional (matching the most amount
possible))
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
本文收集自互联网,转载请注明来源。
如有侵权,请联系[email protected] 删除。
编辑于
相关文章
Related 相关文章
- 1
正则表达式从具有多个 url 的字符串中获取图像 URL
- 2
使用正则表达式获取带有大写符号的字符串迅速的URL
- 3
在 URL 中最后出现 / 后使用正则表达式获取字符串
- 4
从html解析的正则表达式,如何获取特定的字符串?
- 5
从html字符串中使用正则表达式获取样式属性
- 6
如何使用正则表达式从字符串中获取数字?
- 7
如何使用正则表达式从字符串中获取数字
- 8
如何使用JavaScript正则表达式从字符串获取域
- 9
如何使用正则表达式获取tcl字符串的元素
- 10
如何使用正则表达式从字符串中获取浮点值?
- 11
如何使用正则表达式从字符串中获取数字?
- 12
如何使用javascript正则表达式从字符串中获取域
- 13
如何使用正则表达式获取子字符串
- 14
如何通过使用正则表达式从字符串中获取特定值
- 15
如何使用正则表达式获取字符串的特定部分
- 16
如何使用正则表达式只获取字符串的特定部分?
- 17
如何使用带有查询字符串的正则表达式来验证URL?
- 18
如何使用带有查询字符串的正则表达式来验证URL?
- 19
使用正则表达式从字符串中获取子字符串
- 20
使用正则表达式从字符串日期获取子字符串
- 21
使用正则表达式获取多个可能字符串的子字符串
- 22
使用正则表达式从输入字符串中获取键值字符串?
- 23
我如何使用正则表达式获取两个特定字符串之间的字符串?
- 24
如何使用正则表达式从框架中定义的输入字符串中获取字符串
- 25
我如何使用正则表达式获取两个特定字符串之间的字符串?
- 26
如何获取正则表达式以返回字符串(不是正则表达式对象)?
- 27
在C#中使用正则表达式(正则表达式)从字符串获取值
- 28
正则表达式-获取部分字符串
- 29
Python正则表达式从字符串中获取所有图像src'
我来说两句