如何在python中找到所有可能的正则表达式匹配项?
沃尔夫·沃斯
我正在尝试使用python及其正则表达式查找所有可能的单词/标记对或其他嵌套组合。
sent = '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))'
def checkBinary(sentence):
n = re.findall("\([A-Za-z-0-9\s\)\(]*\)", sentence)
print(n)
checkBinary(sent)
Output:
['(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']
寻找:
['(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))',
'(NNP Hoi)',
'(NN Hallo)',
'(NN Hey)',
'(NNP (NN Ciao) (NN Adios))',
'(NN Ciao)',
'(NN Adios)']
我认为正则表达式公式也可以找到嵌套的括号单词/标记对,但它不会返回它们。我应该怎么做?
mo
实际上,不可能使用正则表达式来做到这一点,因为正则表达式表达了一种由正则语法定义的语言,该语言可以通过非限定性自动机来解决,其中匹配由状态表示;然后要匹配嵌套的括号,您需要能够匹配无限数量的括号,然后拥有一个具有无限数量状态的自动机。
为了解决这个问题,我们使用所谓的下推式自动机,用于定义上下文无关文法。
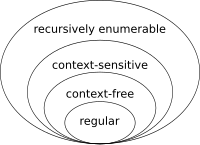
因此,如果您的正则表达式与嵌套括号不匹配,那是因为它表示以下自动机,并且与您输入的任何内容都不匹配:

作为参考,请查看麻省理工学院有关该主题的课程:
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-045j-automata-computability-and-complexity-spring-2011/lecture-notes/MIT6_045JS11_lec04.pdf
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-005-elements-of-software-construction-fall-2011/lecture-notes/MIT6_005F11_lec05.pdf
- http://www.saylor.org/site/wp-content/uploads/2012/01/CS304-2.1-MIT.pdf
因此,有效解析字符串的方法之一是为嵌套括号建立语法(pip install pyparsing第一个):
>>> import pyparsing
>>> strings = pyparsing.Word(pyparsing.alphanums)
>>> parens = pyparsing.nestedExpr( '(', ')', content=strings)
>>> parens.parseString('(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))').asList()
[['NP', ['NNP', 'Hoi'], ['NN', 'Hallo'], ['NN', 'Hey'], ['NNP', ['NN', 'Ciao'], ['NN', 'Adios']]]]
注意:存在一些正则表达式引擎,它们确实使用下推实现嵌套的括号匹配。默认的pythonre引擎不是其中之一,但是存在一个替代引擎,称为regex(pip install regex),它可以进行递归匹配(这使得re引擎上下文不受约束),请参见以下代码段:
>>> import regex
>>> res = regex.search(r'(?<rec>\((?:[^()]++|(?&rec))*\))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))')
>>> res.captures('rec')
['(NNP Hoi)', '(NN Hallo)', '(NN Hey)', '(NN Ciao)', '(NN Adios)', '(NNP (NN Ciao) (NN Adios))', '(NP (NNP Hoi) (NN Hallo) (NN Hey) (NNP (NN Ciao) (NN Adios)))']
本文收集自互联网,转载请注明来源。
如有侵权,请联系[email protected] 删除。
编辑于
相关文章
Related 相关文章
- 1
在字符串中找到的正则表达式替换匹配项
- 2
如何在文件中查找所有正则表达式匹配项
- 3
生成正则表达式的所有匹配项
- 4
WPF在XPS文档中找到所有正则表达式匹配项
- 5
正则表达式在单词后而不是文本中找到匹配项
- 6
Java正则表达式匹配器未找到所有可能的匹配项
- 7
python正则表达式,用于查找所有匹配项
- 8
C#上的正则表达式未找到CDATA的所有匹配项
- 9
python正则表达式在列表中找到匹配项
- 10
查找所有正则表达式匹配项
- 11
Python正则表达式,如何从字符串中删除所有匹配项
- 12
在perl中找到所有文本匹配正则表达式时如何解决问题?
- 13
如何在python正则表达式中获取所有可能的子组?
- 14
如何在python正则表达式中使用str.contains获得所有匹配项?
- 15
使用正则表达式在r中找到匹配项后如何添加元素?
- 16
正则表达式返回所有匹配项
- 17
正则表达式子方法不会替换python正则表达式中的所有匹配项
- 18
如何在不考虑Ruby中的组的情况下获取所有正则表达式匹配项?
- 19
如何在PHP中获取所有正则表达式匹配项?
- 20
在Perl正则表达式数组中找到未定义的匹配项
- 21
Java正则表达式匹配器未找到所有可能的匹配项
- 22
如何在Python中找到正则表达式的第N个匹配项的起始位置?
- 23
找到所有与正则表达式匹配的部分
- 24
查找所有正则表达式匹配项
- 25
正则表达式不会在PHP中输出所有可能的匹配项
- 26
附加到在字符串[Python]中找到的每个正则表达式匹配项
- 27
如何找到所有匹配所有部分的正则表达式?
- 28
Python:如何使用正则表达式获取所有可能的匹配项
- 29
如何在Javascript中找到与正则表达式匹配的属性?
我来说两句